RWKV (pronounced RwaKuv) is an RNN with great LLM performance and parallelizable like a Transformer. We are at RWKV7-G1 "GooseOne" reasoning model.
It's combining the best of RNN and transformer - great performance, linear time, constant space (no kv-cache), fast training, infinite ctxlen, and free text embedding. And it's 100% attention-free, and a Linux Foundation AI project.

Figure 2: A simple illustration of the update mechanism of a single head of RWKV-7's state. Note that the actual state size is 64 × 64 per head, not 4 × 4.
RWKV-Projects
Misc

RWKV-Papers
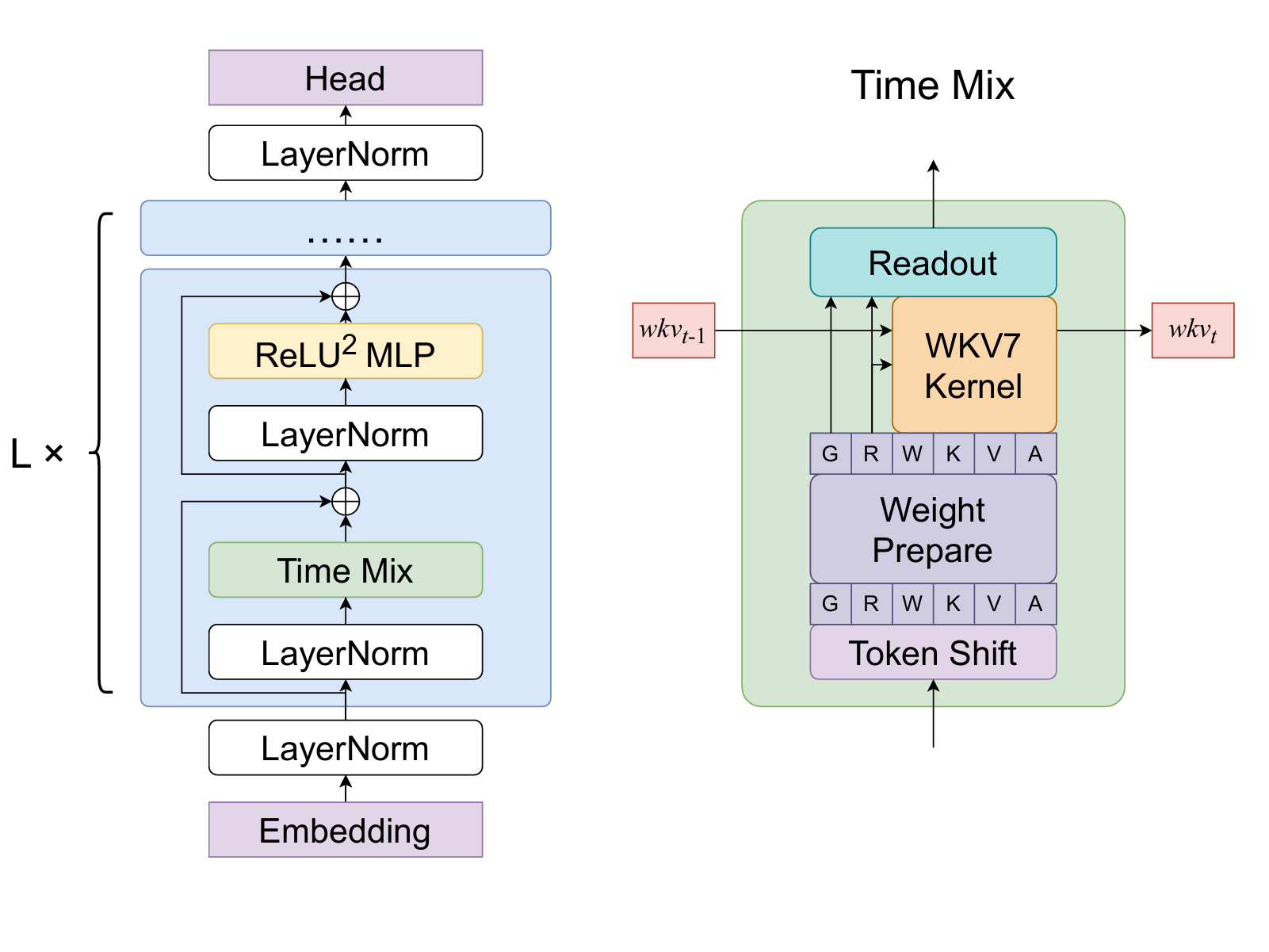
RWKV-7 "Goose" with Expressive Dynamic State Evolution
The paper proposes RWKV-7 "Goose," a novel sequence modeling architecture that achieves state-of-the-art performance in multilingual tasks at the 3 billion parameter scale, matching top English models with significantly fewer training tokens. RWKV-7 requires only constant memory and computation per token during inference, enabling efficient state tracking and recognition of all regular languages. It surpasses Transformer capabilities under standard complexity conjectures and demonstrates strong performance on long-context tasks. The paper also releases a 3.1 trillion token multilingual corpus and pre-trained models ranging from 0.19B to 2.9B parameters, showcasing RWKV-7's scalability and efficiency.
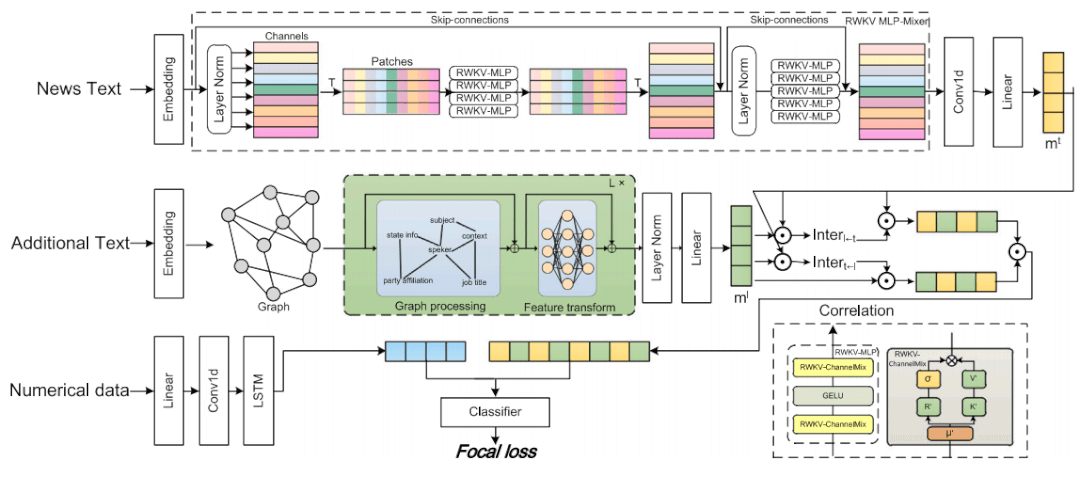
CMGN: Text GNN and RWKV MLP-mixer combined with cross-feature fusion for fake news detection
The paper proposes a novel cross-feature fusion network, CMGN, combining Text Graph Neural Networks (GNN) and RWKV MLP-mixer for fake news detection. The RWKV MLP-mixer processes news text by replacing self-attention with MLP layers to capture deep semantic features, while Text GNN models relationships among supplementary texts (e.g., titles, locations) as graph nodes. A cross-feature fusion mechanism integrates these features dynamically. Evaluated on LIAR, FA-KES, IFND, and CHEF datasets, CMGN outperforms existing methods, demonstrating enhanced accuracy. Focal loss addresses class imbalance, and ablation studies confirm RWKV's critical role in feature extraction. The model advances fake news detection by synergizing graph-based relational modeling and efficient text-sequence processing via RWKV.
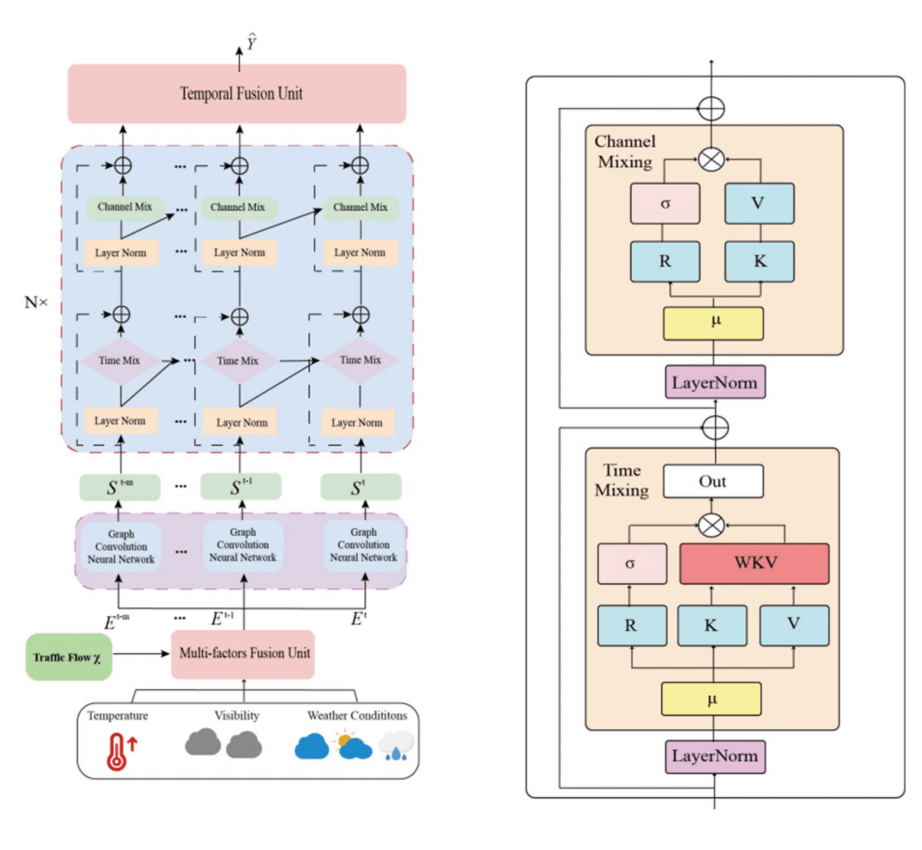
Linear attention based spatiotemporal multi graph GCN for traffic flow prediction
The paper proposes LASTGCN, a deep learning model for traffic flow prediction, integrating a Multi-Factor Fusion Unit (MFF-unit) to dynamically merge meteorological data, a multi-graph convolutional network for spatial correlations, and the Receptance Weighted Key Value (RWKV) block. The RWKV mechanism replaces traditional Transformer attention with linear attention, reducing computational complexity while efficiently capturing long-term dependencies in traffic sequences. By combining RWKV's parallelizable training and RNN-like inference, the model achieves high efficiency for mid-term traffic management. Experiments on real-world datasets (PeMSD) demonstrate superior accuracy and robustness, especially for long-term predictions, outperforming state-of-the-art methods. External factors like weather integration further enhance performance.
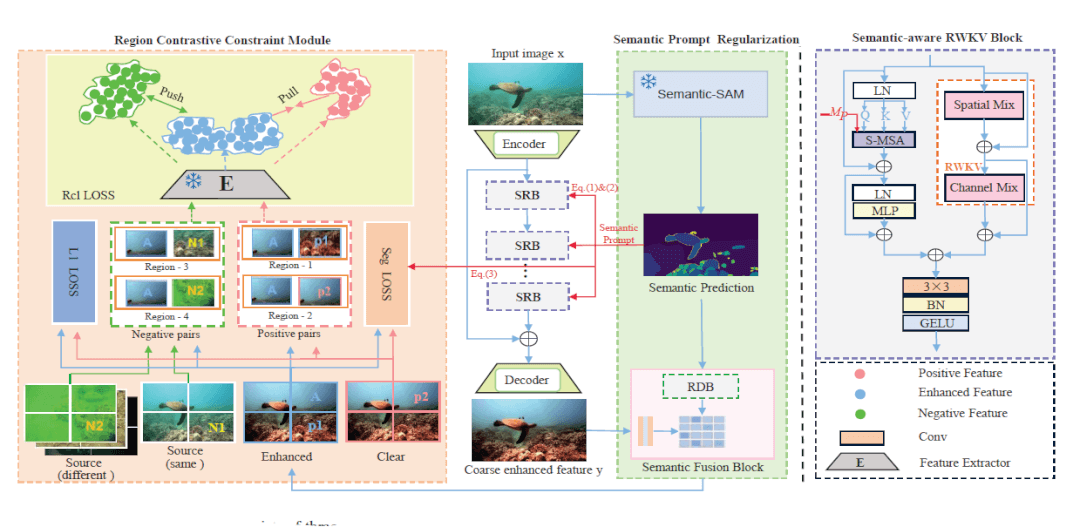
Toward Comprehensive Semantic Prompt for Region Contrastive Learning Underwater Image Enhancement
The paper proposes SRCNet, an underwater image enhancement network integrating semantic guidance and region contrastive learning. The method introduces a semantic-aware RWKV block that leverages the global perception capability of RWKV architecture while incorporating semantic prompts to preserve regional color consistency and structural details. By combining RWKV's efficient attention mechanism with semantic-aware constraints, the network reduces interference from irrelevant pixels across different underwater regions. A novel region contrastive learning strategy further enhances degradation-sensitive feature learning through multi-perspective negative sample utilization. Experimental results demonstrate superior performance over state-of-the-art methods in restoring color accuracy and detail clarity for underwater images.
RWKV-7 explained



RWKV-7 illustrated

RWKV-6 illustrated
